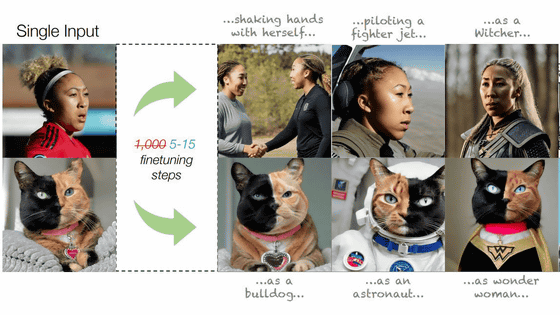
Stable Diffusion과 같은 이미지 생성 AI는 생성하려는 이미지를 “최적화”하여 모든 이미지와 유사하게 만들 수 있습니다. Tel Aviv University의 컴퓨터 과학자 Rinnon Gal리농갈) 팀은 하나의 이미지만을 이용하여 5~15단계의 조정을 수행하는 이미지 최적화 방법을 제안하였다.
(2302.12228) 텍스트-이미지 모델의 빠른 개인화를 위해 설계된 인코더
텍스트-이미지 모델의 빠른 개인화를 위해 설계된 인코더
Text-to-image 개인화는 사전 훈련된 확산 모델을 교육하여 새로운 사용자 제공 개념을 추론하고 자연어 단서에 따라 새로운 시나리오에 삽입하는 것을 목표로 합니다.그러나 현재의 개인화 방법은 긴 tr로 어려움을 겪고 있습니다.
arxiv.org
텍스트-이미지 모델의 빠른 개인화를 위한 인코더 기반 도메인 적응
텍스트-이미지 모델의 빠른 개인화를 위한 인코더 기반 도메인 적응
Text-to-image 개인화는 사전 훈련된 확산 모델을 교육하여 새로운 사용자 제공 개념을 추론하고 자연어 단서에 따라 새로운 시나리오에 삽입하는 것을 목표로 합니다.그러나 현재의 개인화 방법은 긴 tr로 어려움을 겪고 있습니다.
tweakcoder.github.io
Stable Diffusion을 이용한 이미지 최적화 기법 중 하나는 텍스트 반전보지 않았다.이러한 Textual Inversion은 “Embeddings(임베딩)”이라고도 불리는 기술로 꾸준히 확산되고 있습니다. 모델 데이터와 별도로 이미지에서 학습된 데이터를 준비하는 것만으로 특정 이미지와 가장 유사한 이미지를 생성할 수 있습니다.Textual Inversion은 키워드 벡터화에서 “가중치”만 업데이트하므로 학습에 필요한 메모리가 상대적으로 적다는 장점이 있습니다.

그리고 구글의 이미지 생성 AI’영상(이미지 확산 모델에 대한 텍스트)’을 위해 개발된 이미지 최적화 기술드림 부스‘못봤다. Textual Inversion과 달리 Dream Booth는 모델 자체에서 추가 교육을 수행하여 매개변수를 업데이트합니다. 확산을 안정화하기 위해 이 드림부스에 적용할 수 있는 방법을 개발하였으며, “드림부스 구이”와 같은 툴을 이용하여 누구나 쉽게 드림부스를 운영할 수 있습니다.
https://github.com/smy20011/dreamboth-gui
GitHub – smy20011/dreambooth-gui
GitHub에서 계정을 생성하여 smy20011/dreamboth-gui 개발에 기여하십시오.
github.com
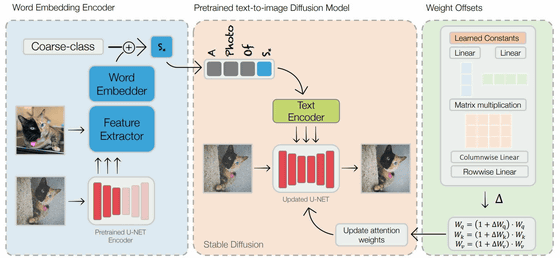
그러나 Rinnon Gal 씨는 “기존의 이미지 최적화 방법은 학습 시간이 길고 스토리지 요구 사항이 높다”고 지적했습니다. 이러한 문제를 해결 “인코더 기반 도메인 조정 방법“제안하고 있습니다.
Stable Diffusion은 ‘텍스트 인코더’에서 입력된 텍스트를 768차원의 토큰 임베딩 벡터로 출력하고, 토큰 임베딩 벡터를 ‘U-NET 인코더’를 통해 잠재 공간의 노이즈 이미지 정보로 변환하여 노이즈 이미지로 변환한다. 디코더를 통해 정보가 출력되는 노이즈 이미지 정보는 픽셀 이미지로 생성됩니다.

Rinnon Gal의 방법은 입력 이미지와 해당 이미지를 나타내는 단어의 조합을 텍스트 인코더에 추가하고 U-NET 인코더를 업데이트하여 벡터의 가중치를 변경하는 두 단계로 구성됩니다.
아래는 연구원의 머그샷을 Stable Diffusion으로 읽어 실제로 유사한 이미지를 생성한 결과를 요약한 것입니다.
왼쪽부터 “이미지 입력”, “안정 확산”, “텍스트 반전”, “드림 부스”, “텍스트 반전 + 드림 부스”, “갈의 접근”.
Mr. Gower의 접근 방식으로 생성된 이미지는 입력된 사람의 얼굴을 상당히 충실하게 재현할 수 있음을 알 수 있습니다.

또한 갈씨의 방식은 사람의 얼굴 외에도 가능하며, 화풍은 유지하면서 변화시킬 대상만 나타내거나, 반대로 대상은 그대로 두고 화풍을 바꾸는 것도 가능한 것으로 확인되었다. .


그러나 Mr. Gall에 따르면 이 인코더 기반 접근 방식은 VRAM에 필요한 용량을 크게 증가시킵니다. 또한 텍스트 인코더와 U-NET 인코더 모두 튜닝을 해야 하므로 메모리가 많이 필요하다.
현재 Gall은 이 방법을 구현하는 코드를 공개하지 않았지만 곧 GitHub에 공개할 것이라고 말했습니다.